Abstract
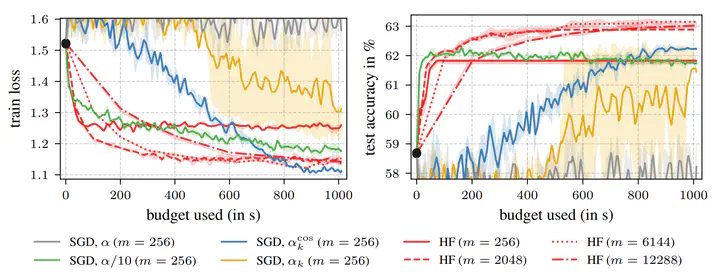
Towards the end of training, stochastic first-order methods such as SGD and Adam go into diffusion and no longer make significant progress. In contrast, Newton-type methods are highly efficient close to the optimum, in the deterministic case. Therefore, these methods might turn out to be a particularly efficient tool for the final phase of training in the stochastic deep learning context as well. In our work, we study this idea by conducting an empirical comparison of a second-order Hessian-free optimizer and different first-order strategies with learning rate decays for late-phase training. We show that performing a few costly but precise second-order steps can outperform first-order alternatives in wall-clock runtime.
Frank Schneider
Postdoctoral Researcher
I am a postdoc in the Methods of Machine Learning group at the University of Tübingen working on training methods for deep learning.